Semi Supervised YOLOv2
Summary
This project was carried out during an internship at IRIT, Toulouse, with Axel Carlier as tutor.
YOLOv2
The fisrt part of this project was about obtaining a functional and trainable model for image detection based on YOLOv2 1. This was done by extracting and adapting code snippets from an existing implementation to a Jupyter Notebook.
Results
I obtained, on the WildLife dataset, the following quantitative results :
| YOLOv2 (30 epochs) | ||
|---|---|---|
| validation mAP | 0.65 | |
| buffalo mAP | 0.59 | |
| elephant mAP | 0.59 | |
| rhino mAP | 0.77 | |
| zebra mAP | 0.64 | |
| training mAP | 0.73 | |
| buffalo mAP | 0.85 | |
| elephant mAP | 0.59 | |
| rhino mAP | 0.89 | |
| zebra mAP | 0.61 |
And qualitative results :


Semi-supervised Learning for Image Detection
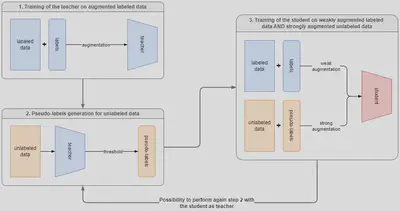
The second part of this project was the implementation of a semi-supervised training for object detection 2 on this functional model. This affected the loss of the model ; initially YOLOv2 has the following loss :
$$ \begin{align} l_{\textrm{yolo}} &= \lambda_{\textrm{coord}} \sum_{i=0}^{S^2} \sum_{j=0}^B \mathbb{1}_{ij}^{\textrm{obj}} \left[ \left( x_{ij} - \hat x_{ij} \right)^2 + \left( y_{ij} - \hat y_{ij} \right)^2 \right] \\ &+ \lambda_{\textrm{coord}} \sum_{i=0}^{S^2} \sum_{j=0}^B \mathbb{1}_{ij}^{\textrm{obj}} \left[ \left( \sqrt w_{ij} - \sqrt{\hat w_{ij}} \right)^2 + \left( \sqrt h_{ij} - \sqrt{\hat h_{ij}} \right)^2 \right] \\ &+ \lambda_{\textrm{obj}} \sum_{i=0}^{S^2} \sum_{j=0}^B \mathbb{1}_{ij}^{\textrm{obj}} \left( C_{ij} - \hat C_{ij} \right)^2 \\ &+ \lambda_{\textrm{noobj}} \sum_{i=0}^{S^2} \sum_{j=0}^B \mathbb{1}_{ij}^{\textrm{noobj}} \left( C_{ij} - \hat C_{ij} \right)^2 \\ &+ \lambda_{\textrm{class}} \sum_{i=0}^{S^2} \sum_{j=0}^B \mathbb{1}_{ij}^{\textrm{obj}} \sum_{c \in \textrm{classes}} \left( p_{ij}(c) - \hat p_{ij}(c) \right)^2 \\ \end{align} $$ where $ \hspace{1em} \mathbb{1}_{ij}^{\textrm{noobj}} = 1 - \mathbb{1}_{ij}^{\textrm{obj}} \hspace{1em} \forall (i, j) \in S^2 \times B $
But to in order take into account the pseudo-labels generated by the teacher, I modified the loss as follows :
$$ \begin{align} l_{\textrm{yolo_ssl}} &= \sum_{i=0}^{S^2} \sum_{j=0}^B \left( \mathbb{1}_{ij}^s \lambda_s + \mathbb{1}_{ij}^u \lambda_u \right) l_{ij} \\ l_{ij} = &\lambda_{\textrm{coord}} \mathbb{1}_{ij}^{\textrm{obj}} \left[ \left( x_{ij} - \hat x_{ij} \right)^2 + \left( y_{ij} - \hat y_{ij} \right)^2 \right] \\ + &\lambda_{\textrm{coord}} \mathbb{1}_{ij}^{\textrm{obj}} \left[ \left( \sqrt w_{ij} - \sqrt{\hat w_{ij}} \right)^2 + \left( \sqrt h_{ij} - \sqrt{\hat h_{ij}} \right)^2 \right] \\ + &\left[ \lambda_{\textrm{obj}} \mathbb{1}_{ij}^{\textrm{obj}} (1 - \mathbb{1}_{ij}^{\textrm{noobj}}) + \lambda_{\textrm{noobj}} \mathbb{1}_{ij}^{\textrm{noobj}} \right] \left( C_{ij} - \hat C_{ij} \right)^2 \\ + &\lambda_{\textrm{class}} \mathbb{1}_{ij}^{\textrm{obj}} \sum_{c \in \textrm{classes}} \left( p_{ij}(c) - \hat p_{ij}(c) \right)^2 \\ \end{align} $$ where $ \hspace{1em} \mathbb{1}_{ij}^{\textrm{obj}} = 1 \hspace{1em} $ for all labeled and unlabeled boxes that contain an object, and $ \hspace{1em} \mathbb{1}_{ij}^{\textrm{noobj}} = 1 \hspace{1em} $ for all labeled and unlabeled boxes that does not contain an object and all unlabeled boxes for which the teacher has a confidence below a certain threshold.
Results
I obtained the following results :
| Teacher (60 epochs) | Student (30 epochs) | Student² (30 epochs) | |
|---|---|---|---|
| training mAP | 0.79 | 0.82 | 0.81 |
| validation mAP | 0.67 | 0.70 | 0.68 |
Showing proof of concept that the student performs better than the teacher, but also that using the student to train a new student (Student² here) does not seem to make any improvement.
J. Redmon and A. Farhadi, “YOLO9000: Better, Faster, Stronger,” 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 2017, pp. 6517-6525, https://doi.org/10.1109/CVPR.2017.690. ↩︎
Sohn, K., Zhang, Z., Li, C., Zhang, H., Lee, C., & Pfister, T. (2020). A Simple Semi-Supervised Learning Framework for Object Detection. https://arxiv.org/abs/2005.04757. ↩︎